Error/Fix: SQL Server has encountered 26063 occurrence(s) of I/O requests taking longer than 15 seconds to complete
Recently I received an incident for CheckDB job failure on one of our production server. Job history suggested that the job has been continuously failing for past 15 weeks. But, no significant message was found in job history. So I started checking SQL Server Error logs, and encountered error message similar to below:-
SQL Server has encountered 26063 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [E:\Data\MyDB2.ndf] in database [MyDB]. The OS file handle is 0x0000000000000A04. The offset of the latest long I/O is: 0x00009ef4c0c000
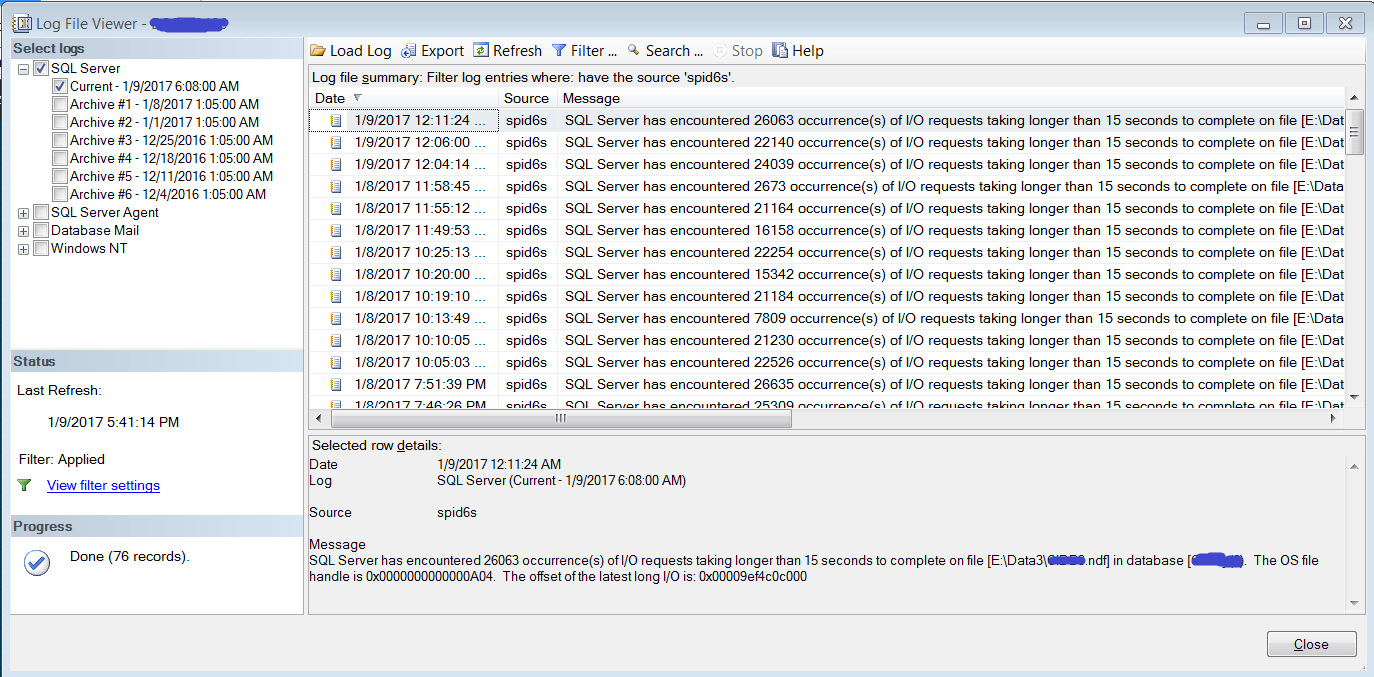
My first thought was that this is surely issue of slow storage. But, as usual with any other issue, there was a but. Could it be that SQL Server is trying to read more than needed data? So, there was a possibility that above error message could be due to slow CheckDB or database corruption. I consulted my team lead looking for his advice on same. He suggested to dig further into SQL Server Error log, and find anything related to CheckDB. So, looking further I found multiple instances of below 3 error messages:-



Resolution:
As hinted in above error messages, I checked TempDB data files configuration and found that all the data files were limited to a fixed size with auto growth disabled. Enabling the auto growth of all the data files, and re-running the CheckDB solved my CheckDB job failure issue.
Friends, please feel free to correct me by comments. If you like the article, do Like & Share. Happy Coding 🙂
Related Posts




About The Author
Ajay Dwivedi
I am Microsoft Certified Professional having 10+ years of experience in SQL Server Querying, Database Design, and Administration. I am fond of Query Tuning and like to automate things using TSQL & PowerShell. I also have experience of implementing end-to-end Data Warehouse solution, and Data Migration using ETL tools SQL Server Integration Services (SSIS), Pentaho Business Analytics, and have designed Database Inventory through PowerShell, Python, and Django etc.
hi ajay,
“I’m also facing “SQL Server has encountered 1 occurrence(s) of I/O requests taking longer than 15 seconds to complete on file [D:\TEMPDB\tempdb2.ndf] in database id 2. The OS file handle is 0x0000000000000D88. The offset of the latest long I/O is: 0x000000041f0000”
Environment: SQL 2014 SP2 – cluster
Disk : SAN
Recently we facing this issue, Please help me how to fix.