![Query Optimization 02 – Questions and Answers per Month [StackOverflow]](https://i0.wp.com/ajaydwivedi.com/wp-content/uploads/2016/11/Sort-Spill-01.png?fit=576%2C349&ssl=1)
Hi Friends, this is my 2nd blog post of series Query Optimization. In 1st blog post What is my accepted answer percentage rate, we took optimization decision based on Logical Reads as our key performance parameter.
In this post as well, we are going to optimize another query from data.stackexchange.com. Below is the query to optimize-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
-- Questions and Answers per Month select [Month], sum(case when PostTypeId = 1 then 1 else 0 end) Questions, sum(case when PostTypeId = 2 then 1 else 0 end) Answers from ( select CAST( cast(DATEPART(YYYY, CreationDate) as varchar) + '-' + cast(DATEPART(MM, CreationDate) as varchar) + '-01' as datetime) [Month], PostTypeId from Posts p ) as X group by [Month] order by [Month] asc |
Since the query seems quite simple so let’s proceed to analyze IO and Time stats results using statisticsparser.com obtained after execution of the query.
 Actual Execution Plan for query (in SSMS) is-
Actual Execution Plan for query (in SSMS) is-
 In SQL Sentry Plan Explorer-
In SQL Sentry Plan Explorer-

Analyzing the actual execution plan, we can see that there is a Stream Aggregate operator. A Stream Aggregate operator groups rows by one or more columns and then calculates one or more aggregate expressions returned by the query. The Stream Aggregation is very fast because it requires an input that has already been ordered by the columns specified in the GROUP statement. If the aggregated data is not ordered, the Query Optimizer can firstly use a Sort operator to pre-sort the data, or it can use pre-sorted data from an index seek or a scan.
Similarly, in our case as well, there is a Sort Operator appearing just before Stream Aggregate Operator. But, why the Sort Operator has cost of 22.7% and a yellow coloured exclamation mark <!> signaling some warning. Checking the Warning under Sort Operator property, we can conclude that due to the huge data size, SQL Server decided to use [TempDB] to perform Sorting of <29,499,660> rows (approx. 647 MB) required for Stream Aggregate Operator. This is called TempDB Spill.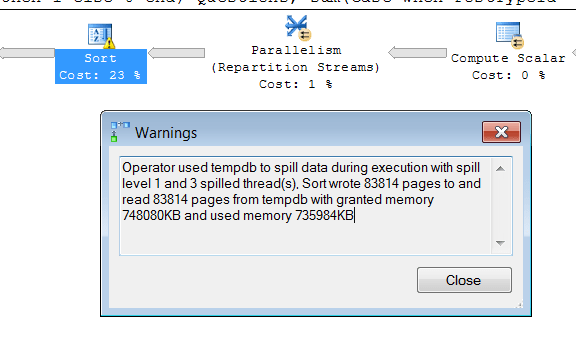
So, let’s modify the query to filter out huge count of rows resolving this problem of tempdb spill. Consider below query-
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
-- Query 02 - Using Group By To remove TempDB spill over for Sort Operator DBCC FREEPROCCACHE DBCC DROPCLEANBUFFERS SET STATISTICS IO ON; SET STATISTICS TIME ON; SELECT CAST(CAST(YEAR(p.CreationDate) as VARCHAR)+'-'+CAST(MONTH(p.CreationDate) AS VARCHAR)+'-01' AS DATE) as [Month], sum(IIF(PostTypeId = 1,1,0)) as Questions, sum(IIF(PostTypeId = 2,1,0)) as Answers FROM dbo.Posts as p WHERE p.PostTypeId IN (1,2) GROUP BY YEAR(p.CreationDate), MONTH(p.CreationDate) ORDER BY YEAR(p.CreationDate), MONTH(p.CreationDate) |
Stats for query-

Execution plan in SSMS-

Execution plan in SQL Sentry Plan Explorer-

Looking at the actual plan of new query, we can see the relative cost of Sort Operator has reduced to 0.0% from 22.7%. This occurred due to small input size (6 KB) to sort compared to 647 MB earlier. This time SQL Server has introduced another operator called Hash Match performing partial aggregation on data obtained from Clustered Index Scan and resulting a reduced size of data set with combination of group columns.
Due to nice our Estimated Subtree Cost of query has gone down to 5836.89 from 7772.4. Also, SQL Server has started suggesting missing non-clustered index on 2nd query due to huge residual IO caused by Clustered Index Scan.
As last step, let’s create missing index suggested by execution plan-
|
1 2 3 4 5 |
-- Missing Index Details that could improve the query cost by 97.9323%. CREATE NONCLUSTERED INDEX NCI_PostTypeId_Includes ON [dbo].[Posts] ([PostTypeId]) INCLUDE ([CreationDate]) GO |
Now, after non-clustered index creation, query has executed within 7 seconds. Below are the stats and execution plan.


So after our final optimization, our query is performing 80k logical reads instead of 7734k reads earlier, and is executing within 7 seconds.
Conclusion: SQL Server is smart enough to suggest changes in terms of warnings. We just need to interpret and analyze those warning and take appropriate step in order to optimize our query. Happy Coding 🙂
Please feel free to correct me by comments. Mention your approach if it differs from mine. If you like the article, do Like & Share.
ads: http://paydayloandial.com
